A while ago I was asking in Slack if anyone knew how to write CMake files for C++ projects that work across many platforms, including macOS, Ubuntu and Windows. One said that he has done something multiplatform with CMake, but doesn’t remember how and added:
“I hate tooling in development.”
I guess he referred to using CMake. I sort of agree with him but also not. For example, tying yourself in some specific IDE is not very useful. Only knowing how to work with some specific tools not available on many platforms limits the applicability of your skills. Moving to a different ecosystem or platform, requiring different tools will become more difficult and time consuming.
It is better to learn the lower level tools well, those tools which are shared across platforms and ecosystems. Then you can apply and use those wherever you are developing. That is why I prefer using git on command line — though I do have several git GUI tools installed.
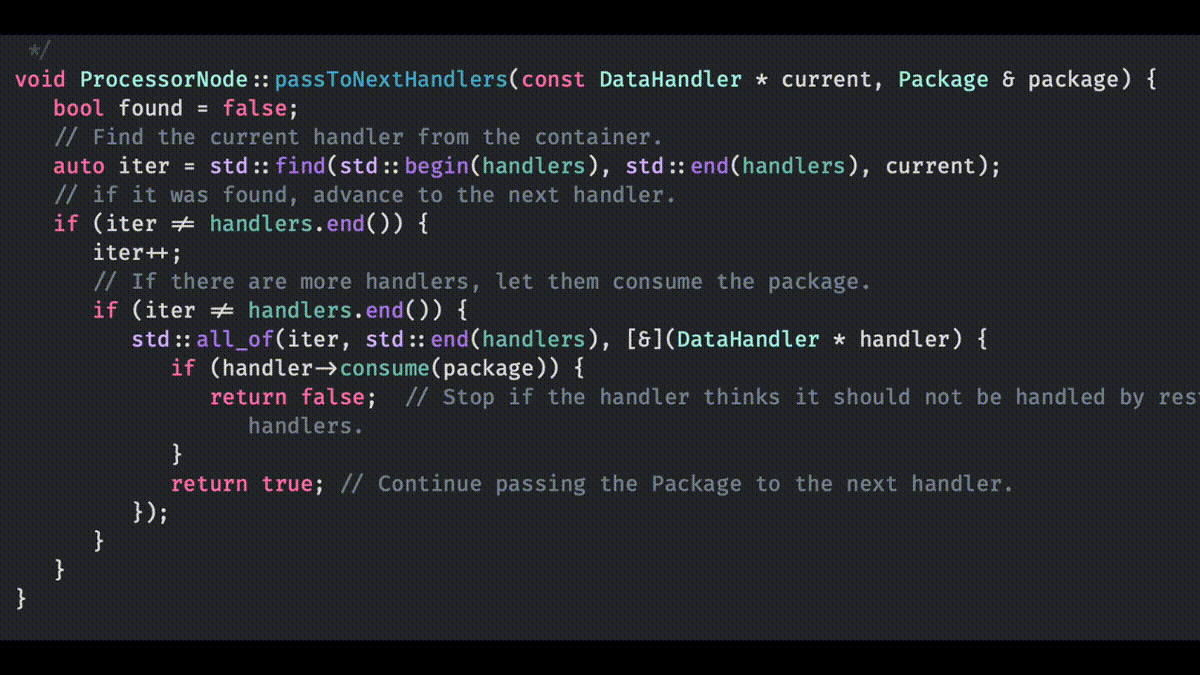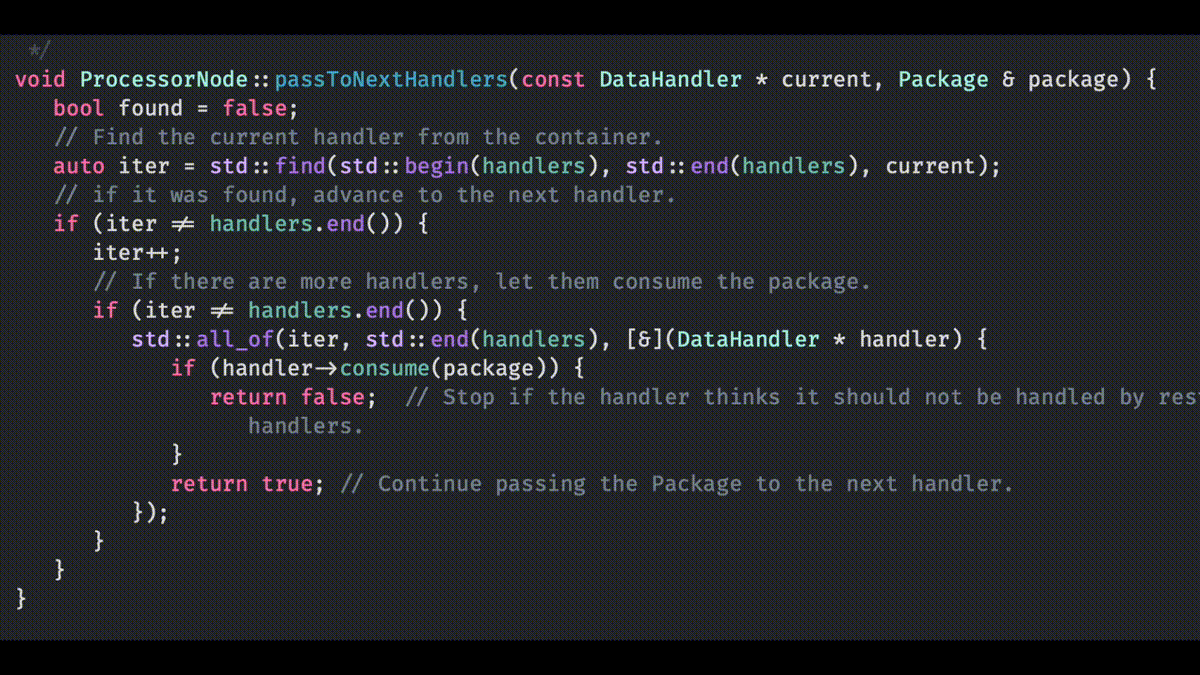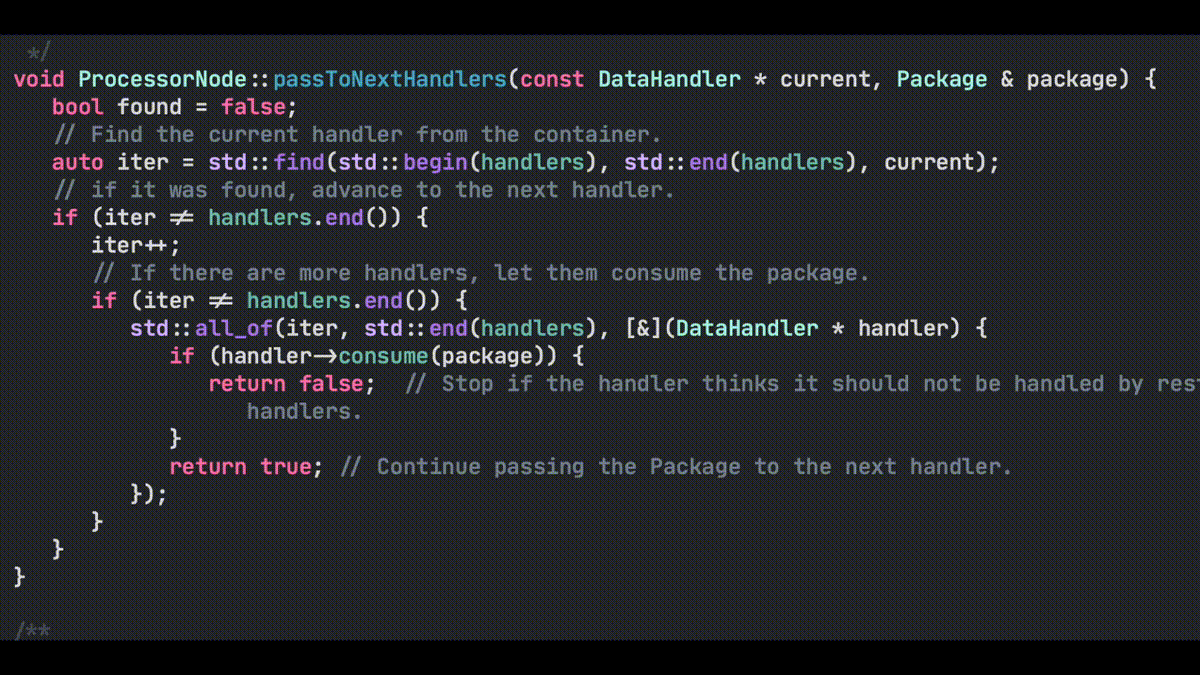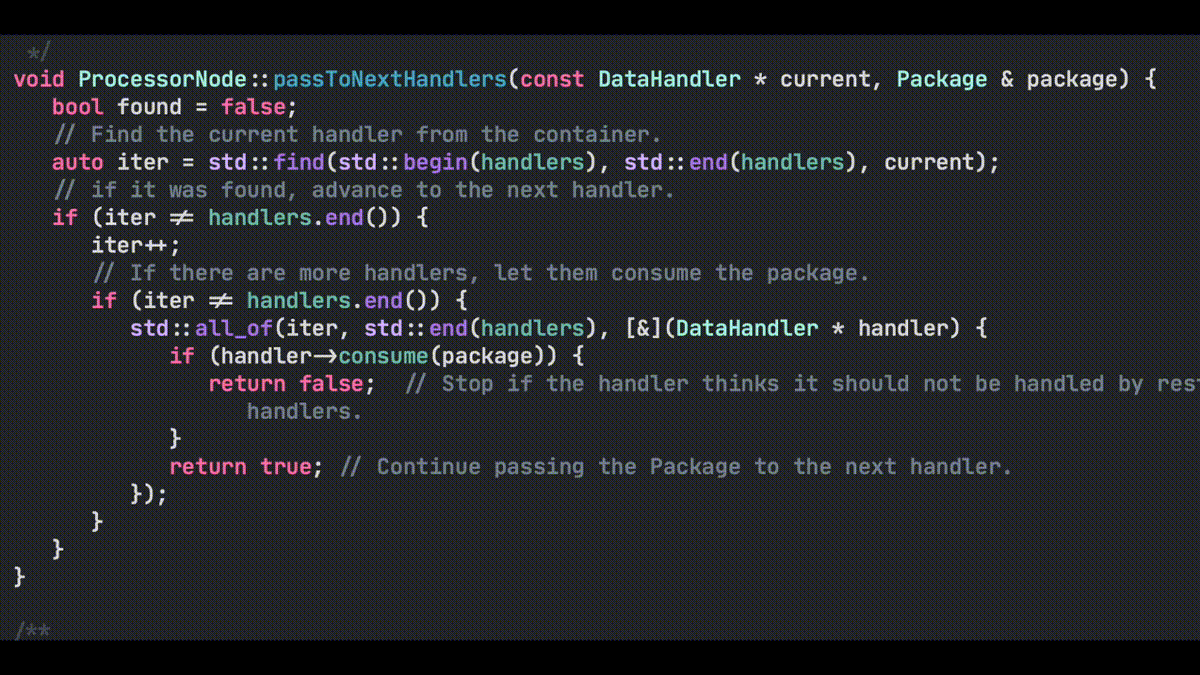
Another thought that came into my mind is that software development without tools just doesn’t happen. We all use tools, whether it is vim, command line git and makefiles, or CMake, Xcode IDE and Fork for git. I prefer to use the tools that fit the problem. Like, if you are doing development for multiple platforms, with multiple compilers and IDEs, then for solving that problem, CMake is a good choice instead of makefiles. It liberates me from the lower level technical stuff of considering how to create makefiles for different OS’s and compilers, allowing me to focus on the actual problem to solve with those tools — creating some code and working systems.
I eventually found the way to create CMake files so that the project I am working on, can be build from the CMake files in Windows 10, Ubuntu and macOS. Also creating projects for Eclipse CDT, Xcode and Visual Studio is quite easy. I can also easily switch from using make to using Ninja as the build engine.
# Creating Ninja build files for a Qt app on macOS from CMake project cmake -GNinja -DCMAKE_PREFIX_PATH=/Users/juustila/Qt/5.12.1/clang_64/lib/cmake .. # Creating MSVC build files on Windows 10 from CMake project cmake -G"Visual Studio 16" -DCMAKE_PREFIX_PATH=C:\Qt\Qt5.14.1\5.14.1\msvc2017_64\lib\cmake;C:\bin .. # Creating Xcode project files on macOS from CMake project cmake -GXcode -DCMAKE_PREFIX_PATH=/Users/juustila/Qt/5.12.1/clang_64/lib/cmake ..
What I learned recently is that it is possible to generate dependency graphs from the CMake project file with GraphViz:
# Create the Xcode project and also a dot file # for generating a dependency graph using GraphViz. cmake -GXcode --graphviz=StudentPassing.dot .. dot -Tpng -oStudentPassing.png StudentPassing.dot

Resulting in a neat graphical representation of the dependencies of your project. Especially handy if you start working with a large system you do not yet know and want to study what libraries and other components it is built using. And teaching software architecture in practice, as I am currently doing: letting students analyse the structure of a system using available tools.
With CMake, I am able to easily combine document generation with Doxygen into the CMake project:
# In your CMakeLists.txt file: find_package(Doxygen) if (DOXYGEN_FOUND) configure_file( ${CMAKE_CURRENT_SOURCE_DIR}/doxyfile.in ${CMAKE_CURRENT_BINARY_DIR}/doxyfile @ONLY) add_custom_target(doc ${DOXYGEN_EXECUTABLE} ${CMAKE_CURRENT_BINARY_DIR}/Doxyfile WORKING_DIRECTORY ${CMAKE_CURRENT_BINARY_DIR} COMMENT "Generating API documentation with Doxygen" VERBATIM ) endif(DOXYGEN_FOUND) # And then generate build files (e.g. for Ninja) cmake -GNinja .. # Do the build ninja # And then generate documentation using Doxygen ninja doc
I began this post with the question about multi platform development, where my problem originally was how to make all this work in Windows while Ubuntu and macOS was no problem.
For Windows, using CMake required some changes to the CMakeLists.txt project files; using CMake macros with add_definitions() due to using random generator engines for Boost uuid class that work differently on Windows than on the other platforms:
if (WIN32)
add_definitions(-DBOOST_UUID_RANDOM_PROVIDER_FORCE_WINCRYPT)
endif(WIN32)Windows also requires some extra steps in the build process, mainly due to the fact that while *nixes have a “standard” location for headers and libs (/usr/local/include and /usr/local/lib), in Windows you should specify with –prefix (Boost) or -DCMAKE_INSTALL_PREFIX (CMake) where your libraries’ public interface (headers, libs, dlls, cmake config files) should be installed and where they can be found by other components.