The goal in part 1 of the puzzle was to find out how many times the word “XMAS” appears in the grid, whether it is written left-to-right, right-to-left or downwards or upwards. And diagonally, from left to right and down, or from right to left and up, as well as from left to right and up, or from right to left and down.
The Matrix implementation has an algorithm to rotate the matrix in steps of 90 degrees. So instead of traversing the grid in all those directions, I rotated it 90 degrees to find out the left-right-up-down and back occurrences of XMAS. After each rotation, I just searched let to right, covering the other directions using rotation
The diagonals are handled in the same way, but in each rotation, I only handled the upper right half of the grid, diagonally where the lines were longer than three characters. I first made the mistake of handling the corner-to-corner line in all rotated diagonals, having too large count of occurrences. When I got to see this mistake, I handled that corner-to-corner diagonal only in one of the rotations.
In all of those cases I ended up with a line, string of characters. What I needed to do then was to find out how many times the line (and the line in reversed order) contains the XMAS.
Part 2 was much more simpler than part 1, so that was quickly solved. The goal was to count how many crosses like this…:
M.S .A. M.S
…the matrix contains.
This required just two loops within, starting from the first line and column from the edge, finishing on second-to-last row and column, check if the cell contains an A and then check if the opposing corners are different and contain M and S.
This was quick on my work laptop (MacBook Pro M2, 2022):
$ swift run -c release AdventOfCode 4 --benchmark Building for production... [1/1] Write swift-version--1AB21518FC5DEDBE.txt Build of product 'AdventOfCode' complete! (0.16s) Executing Advent of Code challenge 4... Part 1: 2549 Part 2: 2003 Part 1 took 0.014584666 seconds, part 2 took 0.002027958 seconds.
The matrix rotations take time, obviously, so part 1 was slower. I considered counting the results of rotated matrices in parallel, but decided not to. That may or may not produce any speed advantage, don’t know… Also could’ve tried to do not rotating in part 1, and just go all in to the matrix from all directions and back to find the words. Well’ it works so I’ll let it be.
So, originally I did this the old school style, parsing the input string character by character, managing the state of processing while discovering the elements from the input string.
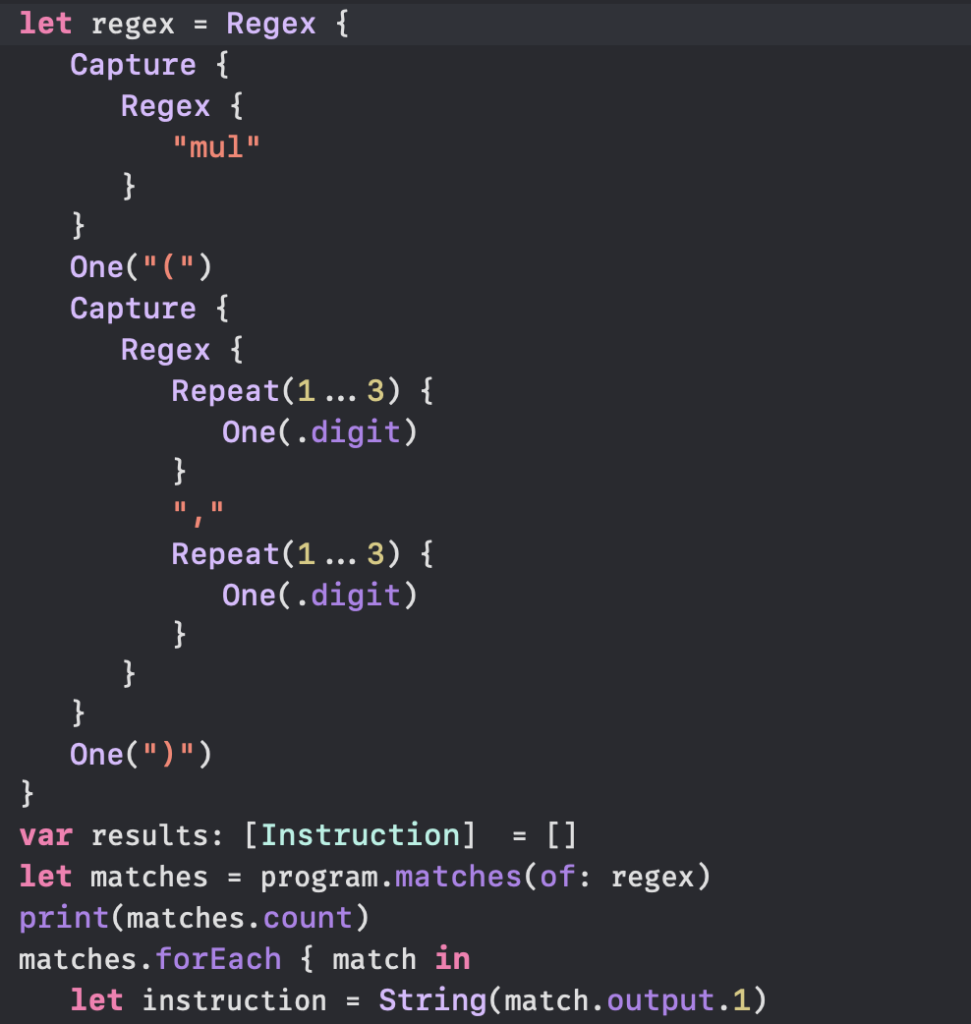
Tonight I reimplemented part 1 using #Swift RegexBuilder. I’ve never been comfortable in using regular expressions (regex) but wanted to give a try.
Snippet of RegexBuilder code showing how to specify what elements to pick from the input string.
Got it working nicely after some hiccups, as usual – wondered why the sum of mul operations was smaller than expected, and it was because I had Repeat(1...2) instead of Repeat(1...3) in the code. Didn’t notice that some mul parameters were three numbers, since in puzzle examples there were only two numbers. So the regex was only picking first two numbers at most from the input :facepalm:
Learned something new. Maybe regexes are not so terrifying things after all…
Today’s puzzle was about parsing. Quite straightforward to implement, having done parsing earlier for different types of structured strings, like tsv, csv, json, xml, etc.
In part 1, I anticipated that part 2 would add parsing some other instructions than mul so I did implement it so. There is an Instruction structure that specifies:
the instruction name
expected number of parameters and
the list of parameter values
Then the instruction is able to evaluate the result. Parsing returns an array of Instructions to execute, and then they are executed, accumulating the result of each mul instruction evaluated:
private struct Instruction {
let instruction: String
let params: Int
var values: [Int] = []
var result: Int {
if instruction == "mul" {
return values.reduce(1, *)
}
return 0
}
}
In part 2, the execution just changes the state; after do instruction, following instructions are evaluated, and after don't, the instructions are ignored, until next do instruction:
$ swift run -c release AdventOfCode 3 --benchmark Building for production... [6/6] Linking AdventOfCode Build of product 'AdventOfCode' complete! (2.55s) Executing Advent of Code challenge 3... Part 1: 188116424 Part 2: 104245808 Part 1 took 0.00304425 seconds, part 2 took 0.004164459 seconds.
I woke up early (not by choice) and read today’s part 1 puzzle description in bed and at breakfast coffee. The part 1 was relatively quick and easy to implement, among replying to emails. Code spoilers below.
Then I had other things to do, went for a run (7 km, really windy, cloudy and partly rainy), then sauna and lunch. I tend to take Monday mornings to myself since I teach from 12 until 18.30.
In between supervising students in Zoom (and handling emails), I worked on the part 2 of the puzzle. I tried to find a fancy mathematical way to handle the part 2 change to part 1. Couldn’t get any of those attempts to work (I am not a math person) so I ended up in recursively trying to remove a single element from the data to see if it then satisfies the puzzle problem.
I’m sure there is a fancy solution using cleverly all the Swift algorithms and data structures etc. My solutions tend to be plain old imperative programming style kind of solutions. Well at least I got it working, and it’s not slow:
$ swift run -c release AdventOfCode 2 --benchmark Building for production... [5/5] Linking AdventOfCode Build of product 'AdventOfCode' complete! (1.84s) Executing Advent of Code challenge 2... Part 1: 663 Part 2: 692 Part 1 took 0.003531042 seconds, part 2 took 0.005103042 seconds.
This year’s puzzles (so far) do not require any especially fast ways to do things, though, data sets are small… Maybe they’ll come later.
Here’s the part 1 solution for today’s puzzle:
func part1() -> Any {
var safeLines = 0
let matrix: Matrix<Int> = parse(data: data)
for lineNumber in 0..<matrix.height {
let line = matrix.elements[lineNumber]
let direction = line[1]! - line[0]!
if abs(direction) > 3 || direction == 0 {
continue
}
var lineIsSafe = true
for columnNumber in 2..<line.count {
let nextDirection = line[columnNumber]! - line[columnNumber - 1]!
if direction.signum() != nextDirection.signum() || abs(nextDirection) > 3 || nextDirection == 0 {
lineIsSafe = false
break
}
}
if lineIsSafe {
safeLines += 1
}
}
return safeLines
}
For Part 2 I implemented a recursive function to solve the partially safe lines to see if changing one level would satisfy the puzzle, limiting the level of recursion so that only one attempt is made to fix an issue in one of the items in the levels by removing it:
private func isSafe(_ line: [Int?], level: Int) -> Bool {
var diffs: [Int] = []
for index in 1..<line.count {
diffs.append(line[index]! - line[index - 1]!)
}
let tooLargeDiffsCount = diffs.filter( { abs($0) > 3 } ).count
let noDiffCount = diffs.filter( { $0 == 0 } ).count
var dirChangeCount = 0
for index in 1..<diffs.count {
if diffs[index] != diffs[index - 1] {
if diffs[index].signum() != diffs[index - 1].signum() {
dirChangeCount += 1
}
}
}
if tooLargeDiffsCount == 0 && noDiffCount == 0 && dirChangeCount == 0 {
return true
} else if level < 1 {
for index in 0..<line.count {
var attempt = line
attempt.remove(at: index)
if isSafe(attempt, level: level + 1) {
return true
}
}
}
return false
}
I might check later how others have solved the puzzle to see if I’d get some inspiration for other styles of solving the puzzle in Swift.
Participating the Advent of Code this year, as far as I am able to. That is, depending on how busy I am at work and at home.
Last year I got 30 stars, about 15 days of participation, last day I got stars (2) was Dec 16th. I missed some second stars for some days. As warmup for this year, I finished one missing second star from last year, now totaling 31 stars out of 50.
For today, the first day, I got two stars:
$ swift run -c release AdventOfCode 1 --benchmark Building for production... ... Build of product 'AdventOfCode' complete! (0.35s) Executing Advent of Code challenge 1... Part 1: 1938424 Part 2: 22014209 Part 1 took 0.000817167 seconds, part 2 took 0.0012365 seconds.
Update (16.40 pm): I took a closer look at the Part 2 and managed to get a significant (relative) performance increase:
Part 1 took 0.000780209 seconds, part 2 took 0.000682292 seconds.
Improved time of 0.000682292 seconds is 55% of the original time of 0.0012365 seconds so almost a half.
The goal here is basically to find how many times a value in table 1 appears in table 2. I first sorted both tables and used Swift filter() to filter out and count the matching values from table 2 (original timing above).
Then I changed it to a simple O(n2) loop without any sorting, which to my surprise performs nicely with the data where n = 1000 (only). That takes about 0.00098nn seconds, usually, better than the original solution using sorting and filtering.
Then I wanted to see how much time I can slice off when adding back sorting of the tables and then use binary search to search for the first occurrence of the value in the second table, and step through the equal values in the table 2, counting how many times they occur. This was the fastest solution. Thought the first was shortest in lines of code, this is much faster.
End update.
Not taking too much stress out of this, not aiming to be fast and do not attempt to be at top of the leaderboards. Today I am 33rd on private SwiftLang leaderboard, but may soon fall down.
I’ve heard last year was more difficult than usual. Last year was my first, and this year I am more prepared. I brought in some utility code I wrote last year to this year project, and also searched for some nice snippets from others, porting some code from other languages to Swift.
Today (Dec 22nd…) I solved the Day 16 puzzle, using a graph data structure that I generalised from Day 8 implementation specific graph. I brute forced the part 2 of the puzzle. Probably would get it much faster if I would modify it to be a little bit more clever solution. Maybe won’t, since who cares.
I am still using Swift, though at some points I’ve considered if I should use C++ or Java. I could then utilise my old code. For example, graph data structure implementations done for teaching, with both Java and C++.
I got left behind at day 12, where the puzzle was the first one I had no idea how to start solving it. Maybe a bit too mathematical to my taste. The overall feeling with this puzzle was “meh…? :/” The first puzzle that I was not even interested to solve. Eventually I did solve the part one, but since brute forcing doesn’t really work with part two, I have not tried since. I did take a look at some solutions with Python and C++ from the community but didn’t follow their examples. I know memoization, it would help here, but with this data…
The next problematic puzzle was day 13, part 2. Part 1 was OK, but again for part 2 I would need to find a faster solution. Also, I do not manage to get the expected result using real data, although the unit tests with test data do pass. Maybe I will return to this after the holidays…?
I agree with those comments in the AoC community that some of the puzzle descriptions and/or test data are deliberately vague, perhaps to prevent or hinder using “AI” in solving the puzzles. The negative impact is that this also creates interpretation problems and requires deep dwelling into the input data. To find out why solutions that pass tests with test data, do not provide the correct answer with the real data. Oftentimes this helps, with the support from insights from the AoC community.
In addition to the generic graph data structure, I also implemented a generic Matrix (or Grid) data structure, to make it easier and faster to parse grid data (2D array) from the input data.
An algorithm to create a Matrix (generic 2D array) of characters from input data string.
When looking at some repositories from people participating for many years in AoC, they often have a good collection of tools to help in solving the puzzles. Since many puzzles are similar to ones in previous years, it helps when you just pick up what you need from the data structures and algorithms you already have, to build the solution. I have avoided the temptation to take these building blocks from others, and built my own. In case I participate again next year.
AoC has been a good learning experience seeing how others approach the problem solving. Like the one where I used a grid of characters. Some saw that you could interpret the symbols in lines of the grid as zeroes and ones, and then handle the data as arrays of bits or rows of integers, and use operations like xor to find differences in lines (arrays of bits/integer values). A thought like this vaguely passed through my mind but I never grasped it but let it pass, and continued away with grid / array based solution. A good reminder for me to consider to stop thinking for a while, instead of storming ahead with some idea that may not actually be so good in solving the puzzle.
Apart from moments of frustration and lack of motivation with some puzzles, AoC has been fun so far. Some participants have commented that this year is more challenging than the previous ones. Probably I’ll try to finish all this year puzzles, although late. Positions in leaderboards are not too important for me, but it is nice to see that I managed to stay in top-50 in Swift leaderboard after checking in day 16 solution.
Probably will fall in position since Christmas preparations are going to start full speed today, and I haven’t bought yet a single present to anyone…. It helps a bit that both my kids and their families are not in town until January and we’ll celebrate with gifts then.
I’ve solved all the puzzles by now, both part 1 and 2. Some have been quite tricky to solve. Other issues I’ve had — mainly stupid parsing problems.
Having an effective parser would be something that helps. Also, as someone suggested in the Swift forums, a (generic) grid would help since apparently many puzzles have a grid to navigate.
Already today I thought that the puzzle could be done using a graph. Went for maps (dictionaries) and arrays again, though. Unfortunately all my graph implementations I could reuse are either in Java or C++, and I’ve been doing everything so far in Swift. Maybe I’ll prepare a Graph struct/class in Swift just to be ready when it is needed….
Today’s part 2 was hard in a sense that the solution took almost eight minutes to run on my Mac Mini M1. Surely there should be a way to optimise. But — won’t do that, I already passed the challenge. I still am busy with teaching, so all these puzzles are done on extra time.
Anyways, today I rose to position 16 on private AoC Swift leaderboard. Even though I am not competing and skipping a day or failing a puzzle is no issue to me, it is nice to see that I do relatively well – so far…
By now I’ve used Sets, Dictionaries, arrays, ranges, string manipulation, string splitting, enumerations, and those grid operations. Let’s see what comes up tomorrow…
For the first time, I started the Advent of Code challenge. I’ll be working with Swift using the AoC project template from Apple folks in GitHub, announced in the Swift discussion forums.
Got the two stars from the first day of the challenge. ? and rewarded myself with the traditional Friday pizza with red wine ??
Part two of day one required some interpretation. I finally got the idea and finished with success.
Don’t want to spoil the challenge but I did the part two in two different ways:
Going through the input string using String.Index, character by character, picking up words of numbers (“one” etc) converting them to digits (“1”) to a result string. This should be O(n) where n is the number of chars in the input data string.
Replacing words using Swift String replaceOccurrences using two different Dictionaries. This has two consecutive for loops iterating two dictionaries replacing text in input string using keys in dictionaries (eg “oneight”) with values (“18”) in dictionaries. This should be O(n*m) where m is the number of entries in the two dictionaries (ca 15 +/- some), n being the number of characters in the input string.
Surprisingly, the first option took 12 secs as using the higher APIs took only 0.007 secs. Maybe I did the first wrong somehow or Swift String index operations are really slow here because of Unicode perfectness. I’ve understood that the collections APIs used with strings are not so picky about Unicode correctness.
Otherwise I used conditional removal of characters that are letters from the string, map algorithms to map the strings containing numbers to integers and reduce algorithm to calculate the sum.
Challenges like this are a good way to brush up my skills. And learn more about Swift. I added myself to the Swift leaderboard to see how other Swift programmers do.
Tomorrow is the day two. Should have time for that in the morning since I wake up early nowadays, both because of myself and the dog. He is already 14+ years and having health issues unfortunately. Meaning early wake-ups every now and then.
The end part of the AoC maybe a real challenge because of all the Christmas hassle in the house. And the busy end of the semester at the university. Interesting to see how far I get and with how many gaps.
So, you can use a Binary Search Tree (BST) to store and quickly access key-value pairs. Usually the key gives the position of the value element in the tree. You place smaller values in the left side, and larger values in the right side of the tree.
A sample BST unbalanced, having 13 nodes in the tree. Key in the BST is the person’s name in ascending order.
Finding by key value is O(log n) operation. Starting from the root node of the tree, comparing the key, you can choose which subtree to continue searching for the key. If the BST is balanced, you need to only do O(log n) comparisons at most to get to the key-value pair you wish to find. Like searching for Jouni Kappalainen takes four comparisons from the root and it is found.
The tree contents in key order shown in a Java Swing table view. Order is by BST key order.
Note that the numbers in each tree node picture above is the number of children of that specific node. For example, Kevin Bacon has zero children, as Samir Numminen has five, and the root node has 12 children.
How about if you want to treat the BST as an ordered collection, each item in the tree accessible by index, as you would do with an array? Like, “give me the 6th element in the tree (element at index 5), when navigating in-order, from smallest to largest key in the tree”. In the sample tree above, Kappalainen would be in the index 5 (zero based indexing). Kevin Bacon’s index would be zero since it is the first element in-order. Root node would be at index 1 in this sample tree.
The obvious thing to do would be to traverse the tree in-order, counting indices from the lowest left side node (Bacon) with index 0 (zero) and then continue counting from there until you are at the index 5 (Kappalainen).
Sample tree with in-order indices added in blue. Compare this to the GUI table order and you see the indices are correct.
This works, but the time complexity of this operation is O(n). If you have, let’s say a million or more elements in the three, that is a lot of steps. Especially if you need to do this repeatedly. Is there a faster way to do this?
The faster way is to use the child counts of the tree nodes to count the index of the current node (starting from the root), and then use that information to decide if you should proceed to left or right subtree to continue finding the desired index. This makes finding the element with an index O(log n) operation, which is considerably faster than linear in-order traversal with O(n).
For example, consider you wish to find element at the index 5. Since the root node’s left child has zero children, we can then deduce that the root node’s index is zero plus one, equals one. Therefore at the root you already know that the element at index 5 must be at the right subtree of the root. No use navigating the left subtree.
Also, when going to the right child from the root, you can calculate the index of that node, Töllikkö. Since Töllikkö is after the root node, add one to the index of root node, therefore the current index being two (2). Then, since all Töllikkö’s left children are in earlier indices, add the child count of Töllikkö’s left subtree, which is 8, to the current index, having current index of ten (10). And since the left child node must be counted too, not just its children, we add another one (1) to current index, it now being 11. So the index of Töllikkö is 11.
Now we know that since we are finding the index 5, it must be in the left subtree of Töllikkö, so we continue there and ignore Töllikkö’s right subtree.
Moving then to Kantonen, we need to deduct one (1) from the current index, since we moved to earlier indices from Töllikkä, current Index being now 10. This is not yet Kantonen’s index. We need to deduct the number of children in Kantonen’s right child + 1 from the current index, and will get 10 – 6, having 4. That is Kantonen’s index.
Since 4 is smaller than 5, we know we need to proceed to the right subtree of Kantonen to find the index 5. Advancing there, in Numminen, we need to add 1 to the current index since we are going “forward” in the index order to bigger indices, as well as the count of children + 1 (the subtree itself) in Numminen’s left subtree, in so current index (Numminen’s) is now 6.
Since 6 < 5 we know to continue searching the index from Numminen’s left subtree there we go (to Kappalainen), deducing one (1) from current index, it now being 5. Now, earlier, when moving to left (to Kantonen), we also deducted the number of children in Kantonen’s right subtree. But since Kappalainen has no right subtree, we deduct nothing.
Now we see that current index is 5, the same we are searching for. So, we can stop the search and return Kappalainen as the element in the index 5 in the tree.
Using this principle of knowing the count of children in each tree node, we can directly proceed to the correct subtree, either left or right, and therefore replacing the linear in-order search with faster logarithmic search. With large data sets, this is considerably faster.
While demonstrating this to students using the course project app TIRA Coders, we saw that loading 1 000 000 coders to the course TIRA Coders app, the O(n) index finding operation (required by the Java Swing table view) made the app quite slow and sluggy. When scrolling, the app kept scrolling long time after I lifted my hand off the mouse wheel. Swing Table view was getting the objects in the visible indices constantly while scrolling and as this is O(n) operation, everything was really, really slow.
When replaced by the O(log n) operation described above, using the app was a breeze even with the same number of one million data elements in the BST; there was no lags in scrolling the table view nor in selecting rows in the table.
So, if you need to access BST elements by the index, consider using the algorithm described above. Obviously, for this to work, you need to update the child counts in parent nodes while adding nodes to the BST. If your BST supports removing nodes and balancing the BST, you need to update the child counts also in those situations.
(I won’t share any code yet, since the students are currently implementing this (optional) feature with the given pseudocode in their BST programming task.)
Two blasts from the past. Sorry for the long post but hey, this is a frigging blog, not some social media service for attention spans of mere seconds.
First “blast”
When teaching (exercise support sessions) over Zoom, we course teachers have a private chat in Slack to coordinate who goes to which breakout room to help students asking for help. When there’s no acute problems to address, we occasionally chat about random topics.
Yesterday I was participating from the bed using my laptop since I’ve got the flu but was well enough to participate somewhat.
I have had this idea to write the Data structures and Algorithms course materials into a book format. Not to be sold in book stores, but just shared to the students as a single PDF / eBook file.
I remembered doing exactly that, very very long time ago in a discontinued course, and happened to mention this to the other teachers in Slack; that I couldn’t find the book in my computer archives.
“Hold my beer”, said one of the teachers, and voilá, he uploaded that course pdf “book” from 1999 to the Slack channel! As it happens, he was at that time or just before, a student on that course and had archived the material! He is a lot better than me in archiving, apparently, so thanks JLa for that! He also participated in teaching (also) this course, as far as I can remember.
A snippet from the course material for Programming environments course.
The course, Programming environments, was originally a Mac programming course, by our Department Mac guru who left us a long time ago to work in the industry (good for him). Then later, I implemented the course for programming with C in Windows (thanks to Petzold’s book). Even later I also implemented a version to teach Symbian C++ programming in Nokia devices.
Anyhows, I liked the idea to provide the material in a “book” format to the students, and even distributed the book in an eBook format for them to read. A total of 45 pages. I wish I’d find the original editable document somewhere from my external backup drives or USB drives, would be fun to have it.
Maybe I’ll do this sometime again for some course. Writing can be fun.
The second “blast”
A thing I did find when browsing through my archives, was a department plan to arrange teaching for the study year 2009-2010.
Especially interesting for me was to check out the list of courses our team (software engineering focused teachers/courses) at the department taught that study year (table below).
I will just list the courses about programming or strongly programming related or strongly technical courses:
Finnish course name
English course name
Algoritmit
Algorithms
C ohjelmointi
Programming in C
C++
C++ programming
Johdatus kääntäjiin
Introduction to compilers
Johdatus ohjelmointiin
Introduction to programming
Johdatus tietorakenteisiin
Introduction to data structures
Logiikka
Logic
Ohjelmistojen testaus
Software testing
Ohjelmointikielten periaatteet
Principles of programming languages
Ohjelmointityö I
Programming assignment I
Ohjelmointityö II
Programming assignment II
Ohjelmointityö III
Programming assignment III
Ohjelmointityö IV
Programming assignment IV
OHJY/MacOS/iPhone
Programming environments / Mac/iPhone
OHJY / Windows
Programming environments / Windows
OHJY / Unix
Programming environments / Unix
OHJY/ Symbian
Programming environments / Symbian
Olio-ohjelmointi
Object oriented programming
Projekti I
Term project for external customers, programming
Projekti II
Term project for external customers, often included programming
Rinnakkainen ohjelmointi
Parallel / concurrent programming
RTCS
Real time computer systems
Tietokantojen perusteet
Introduction to databases
Unix perusteet
Introduction to Unix
In some of those courses, doing actual programming by the students might have been a relatively small part of the course. And some of the courses were not offered every year. Just not to inflate the amount of actual programming done in some of these courses.
But – if you compare these strongly programming focused courses of that time to the list of current programming or strongly technical courses in the study program:
Finnish course name
English course name
Laitteet ja tietoverkot
Devices and Data networks
Ohjelmointi 1
Programming 1
Ohjelmointi 2
Programming 2
Tietorakenteet ja algoritmit
Data Structures and algorithms
Tietokannat
Databases
Ohjelmointi 3
Programming 3
Ohjelmointi 4
Programming 3
Ohjelmistojen laatu ja testaus
Software Quality and testing
Bachelor project
Programming project for external customers
Master’s project
Systems development /analysis project for external customers
So at that time around 2010, we had a total of 24 very technical/programming courses in old study program. Currently we have only 10.
There are courses on software engineering and such nowadays too, but they usually do not include learning to construct things and spending a relatively significant amount of time doing that – that is what I mean by a technical course here, and what was done earlier.
The current study program at the MSc level does not have a single course focused on programming. No more than 5-6 years ago, we still had at least one, Embedded software development environments, focusing (mostly) on distributed mobile programming (taught by me and some other teachers). Before that, we (including me) taught, together with Tampere University of Technology, Mobile systems programming course (Symbian, J2ME). All discontinued.
Currently we have nothing about parallel / concurrent programming in the study program. Last week I did one very small demo to at least show an extremely little thing about concurrency in my course on Data structures and algorithms. To let the students at least to be aware that something like this actually exists and could be done. So like 15 minutes of that topic in the whole study program.
Principles of programming languages, logic, compilers — totally gone from the study program in just over ten years.
You know (and I know) that there are as many opinions than there are you-know-what, but in my personal honest opinion, this is not good. Considering the needs of the local software industry.
Of course the technical topics of today would be perhaps different and obviously should be up to date with modern technologies. But if these kinds of topics and the deeply technical perspective on things is missing, there is not even the chance to discuss if they would or should be updated.

![A code snippet in Swift:
func parse<Character>(data: String) -> Matrix<Character> {
var matrix: Matrix<Character> = Matrix()
data.components(separatedBy: .newlines).forEach { line in
if line.count > 0 {
matrix.append(row: Array(line) as! [Character])
}
}
return matrix
}](https://www.juustila.com/antti/wp-content/uploads/2023/12/Nayttokuva-2023-12-22-kello-11.39.04-1024x356.png)





